Entre los objetivos pueden mencionarse:
- Familiarizarse con las técnicas de reconocimiento basadas en comparación de patrones (Template Matching con Dynamic Time Warping) y en Modelos Ocultos de Markov (Hidden Markov Models) a través de la implementación en Matlab de una aplicación sencilla para el reconocimiento de dígitos aislados del 0 al 9.
- Desarrollar un protocolo para la evaluación de la performance de los algoritmos de reconocimiento, por ejemplo mediante el cálculo de un porcentaje de aciertos, de falso reconocimiento y de falso rechazo, y el cómputo de la matriz de confusión. Opcionalmente puede evaluarse la performance de los algoritmos en presencia de ruido adicionado artificialmente.
- Para las tareas de entrenamiento y reconocimiento se usará la base de datos
compilada durante varios dictados del curso. Cada palabra (dígito) de la base de
datos es un archivo WAV, obtenido grabando, con una tasa de muestreo de
11025 Hz, a 25 locutores repitiendo 3 veces cada dígito. Las seńales han sido procesadas
para reducción de ruido. Los archivos han sido nombrados con la siguiente codificación.
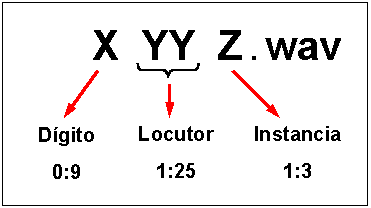
- Base de Datos de Dígitos del 0 al 9 (digitos_11025Hz.rar)
- Se deberá completar la base de datos hasta alcanzar los 50 locutores, con tres instancias de cada dígito por locutor.
- Se implementarán algoritmos para la normalización temporal (Dynamic Time Warping) de los dígitos de entrenamiento y se generarán patrones para cada uno de los dígitos del 0 al 9 usando como vectores característicos los coeficientes cepstral de los dígitos correspondientes, divididos en frames de 20-30 mseg de duración.
- Se implementará un algoritmo reconocimiento basado en comparación de patrones, utilizando la distancia de Mahalanobis como medida de similitud entre el dígito a reconocer y cada uno de los patrones.
- Se evaluará el porcentaje de reconocimiento usando datos que no hayan sido usados en la etapa de entrenamiento.
- Se implementará un algoritmo de reconocimiento basado en HMM. Se utilizará para ello el Hidden Markov Model (HMM) Toolbox for Matlab escrito por Kevin Murphy (1998) (ver http://www.cs.ubc.ca/~murphyk/Software/HMM/hmm.html por detalles). Puede descargar el Toolbox desde aquí .
- Se evaluará el porcentaje de reconocimiento usando datos que no hayan sido usados en la etapa de entrenamiento.
- Se computará la matriz de confusión y se mostrará como una imagen.
- Se comparará la performance de reconocimiento de las dos técnicas implementadas.
Juan Carlos Gómez, Noviembre de 2023.